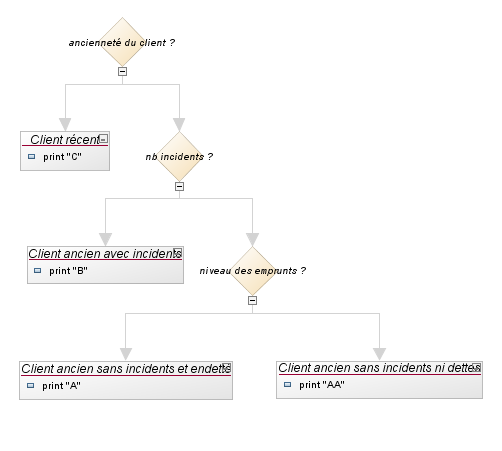
Il y a un cas où l'automatisation partielle est utile. C'est celui où vous n'êtes pas pleinement en mesure de formaliser toute votre logique d'une façon interprétable par la machine ou lorsque les experts ne sont pas vraiment des experts.
Dans ce cas, vous demandez à la machine d’être en mesure de déterminer le niveau de difficulté de la question posée. Si la question posée est un trop difficile la machine est alors capable de dire "je démissionne", si elle est facile, elle répond alors à la question posée, de manière partielle ou complète.
Par exemple, lorsque la couleur est le noir-noir, il est facile de dire que la couleur est noire, lorsque la couleur est le blanc-blanc, il est facile de décider que la couleur est blanche, lorsque la couleur est grise, il n'est pas facile de choisir entre le noir et blanc.
La capacité de dire "je renonce" est utile car vous pouvez commencer à automatiser une décision sans totalement maîtriser la logique de cette décision. Vous pouvez automatiser les réponses faciles et laisser les réponses les plus difficiles aux experts. Avec l'aide de ce modèle, vous pouvez ainsi avoir du temps pour améliorer vos systèmes en continu. Il vous laisse du temps pour formaliser des logiques complexes ou, plus raisonnablement, pour acquérir un peu plus d’expertise.